해쉬 테이블이란
해쉬 테이블
해쉬 테이블은 key에 value를 저장하는 할 수 있는 데이터 구조이다. get(key)를 통해 value를 가져오는 속도가 배열 [index] 속도에 가까울 만큼 매우매우 빠르다.
어떻게 해쉬 테이블에 대한 기본적인 개념을 알아보도록 하겠다.
이름을 키로, 전화 번호를 저장하는 데이터 구조를 만든다고 하자.
배열에 특정 인덱스에 접근하는 것처럼 문자열을 입력하면 바로 전화번호가 O(1)의 속도로 튀어나왔으면 한다.
이 때 만약 이름과 전화번호를 묶어서 링크드 리스트에 저장한다면 원하는 이름을 찾을 때 모든 노드를 탐색해야 한다.
어떤 사람은 이런 생각을 했다. 문자열을 숫자로 바꿀 수 있다면 배열과 인덱스를 사용해서 전화번호로 저장하면 탐색 속도가 빨라지겠지.
우리는 저장하려는 전화번호와 이름이 총 16개가 있다. 이 때 해쉬 함수라는 것을 사용해서 이름을 배열의 인덱스로 사용하고 싶다. hash_function은 문자열을 받아 간단한 연산을 거친후 %16을 통해 0 ~ 15까지 수를 만든다.그 해당 숫자를 배열의 인덱스로 사용해 전화번호를 저장할 수 있다.

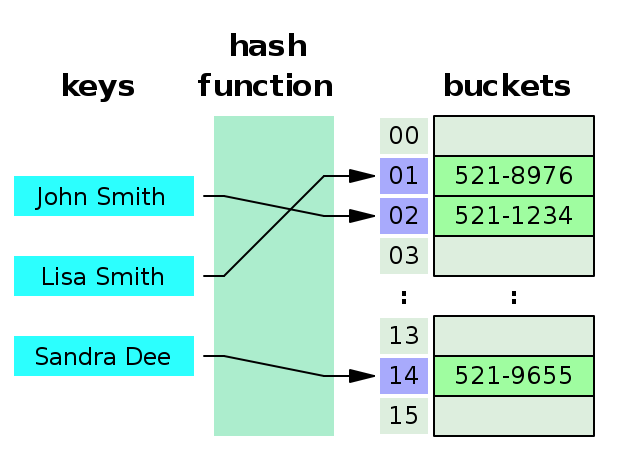
출처 : https://en.wikipedia.org/wiki/Hash_table
John Smith의 데이타를 저장할때, index = hash_function(“John Smith”) % 16 를 통해서 index 값을 구해내고, array[01] = “John Smith의 전화 번호 521-8976”을 저장한다.
이런 형식으로 데이타를 저장하면, key에 대한 데이타를 찾을때, hash_function을 한번만 수행하면 array내에 저장된 index 위치를 찾아낼 수 있기 때문에, 데이타의 저장과 삭제가 매우매우 빠르다.

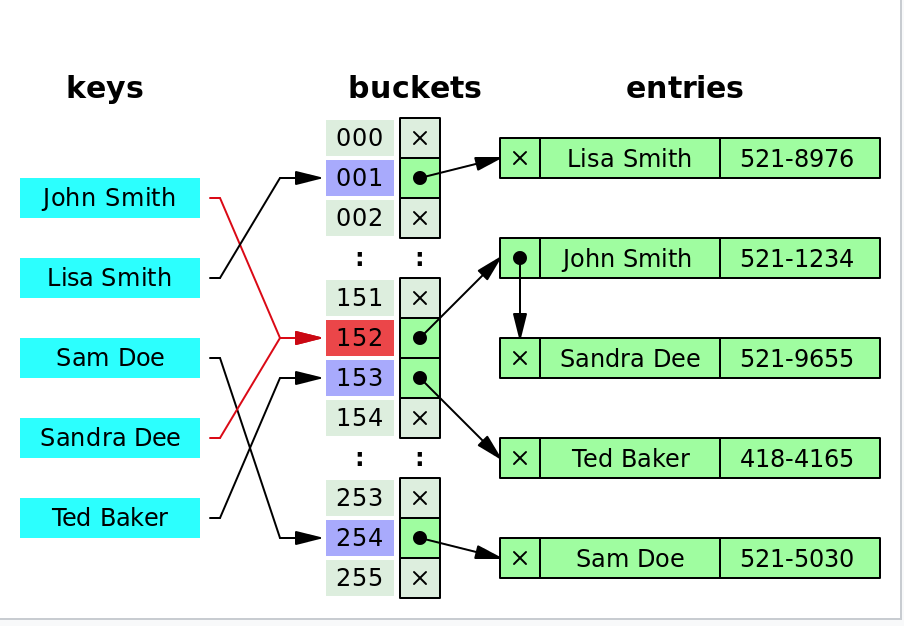
하지만 좀 더 생각해보면 이 방식에는 치명적인 문제점이 있다. hash_function이 완벽하지 않기 때문에 서로 다른 key에 대해서 hash_function(key)가 같은 값으로 발생할 수 있다는 점이다. 만약 John Smith라는 이름과 Sandra Dee라는 이름의 hash_function값이 152로 같다면 문제가 생긴다. 같은 배열 인덱스에 두개의 값이 중복되어 저장되기 때문에 하나의 값이 사라질 것이다.
- Separate chaining 방식 이를 해결하기 위해서 배열의 값을 단일 값으로 저장하지 않고 링크드 리스트를 사용해서 노드를 만들어 연결해 해결할 수 있다. john Smith와 Sandra Dee를 각각 노드로 만들어 연결해 152에 연결되어 있는 상태로 유지하면 된다.
- 해쉬 함수 출력값이 같아도 원래 이름이 다를 수 있다. 이러한 문제를 좀 더 현명하게 해결할 수 없을까?
- 드롭박스, 구글 드라이브에는 수 천만 사용자가 수십 억개의 파일들을 올린다. 예를 들어 동일한 뽀로로 동영상을 만 명의 유저가 드롭박스에 업로드할 때 드롭박스는 정말 만개의 파일을 가지고 있을까? 아니다. 드롭박스나 구글 드라이브는 해쉬 테이블을 사용해서 데이터를 저장한다.
- 그렇다면 서로 다른 동영상을 해쉬 함수 결과가 같게 나오면문제가 생기지 않을까? 위에서처럼 링크드 리스트를 사용할 수도 있겠지만 드롭박스는 더 많은 해쉬 함수를 사용한다고 한다. 1개의 해쉬 함수 결과가 같을 확률보다 5개의 해쉬 함수 결과값이 같을 확률이 훨씬 낮아지기 때문이다.
C언어로 구현해보기
참고 : http://bcho.tistory.com/1072
